Deployment Modes
Chroma runs wherever you need it to, supporting you in everything from local experimentation, to large scale production workloads.- Local: as an embedded library - great for prototyping and experimentation.
- Single Node: as a single-node server - great for small to medium scale workloads of < 10M records in a handful of collections.
- Distributed: as a scalable distributed system - great for large scale production workloads, supporting millions of collections.
Core Components
Regardless of deployment mode, Chroma is composed of five core components. Each plays a distinct role in the system and operates over the shared Chroma data model.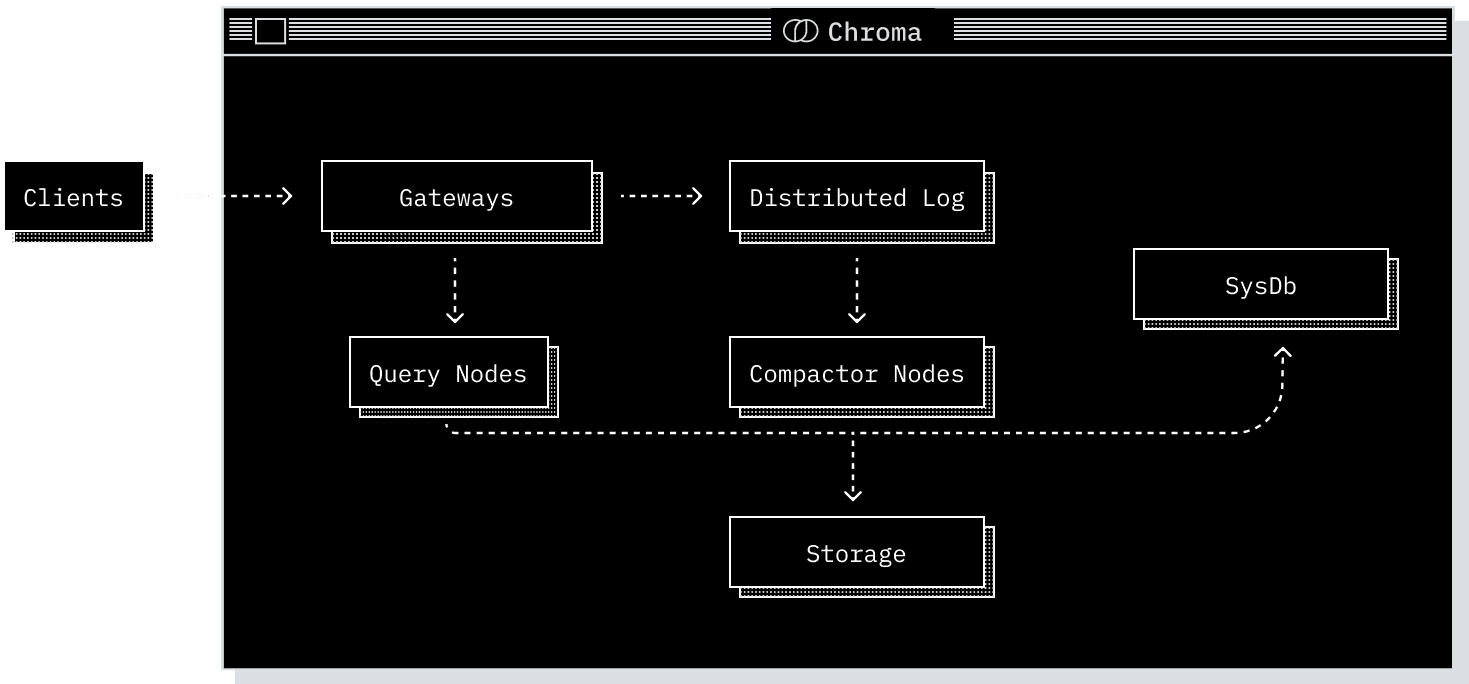
The Gateway
The entrypoint for all client traffic.- Exposes a consistent API across all modes.
- Handles authentication, rate-limiting, quota management, and request validation.
- Routes requests to downstream services.
The Log
Chroma’s write-ahead log.- All writes are recorded here before acknowledgment to clients.
- Ensures atomicity across multi-record writes.
- Provides durability and replay in distributed deployments.
The Query Executor
Responsible for all read operations.- Vector similarity, full-text and metadata search.
- Maintains a combination of in-memory and on-disk indexes, and coordinates with the Log to serve consistent results.
The Compactor
A service that periodically builds and maintains indexes.- Reads from the Log and builds updated vector / full-text / metadata indexes.
- Writes materialized index data to shared storage.
- Updates the System Database with metadata about new index versions.
The System Database
Chroma’s internal catalog.- Tracks tenants, collections, and their metadata.
- In distributed mode, also manages cluster state (e.g., query/compactor node membership).
- Backed by a SQL database.
Storage & Runtime
These components operate differently depending on the deployment mode, particularly in how they use storage and the runtime they operate in.- In Local and Single Node mode, all components share a process and use the local filesystem for durability.
- In Distributed mode, components are deployed as independent services.
- The log and built indexes are stored in cloud object storage.
- The system catalog is backed by a SQL database.
- All services use local SSDs as caches to reduce object storage latency and cost.
Request Sequences
Read Path
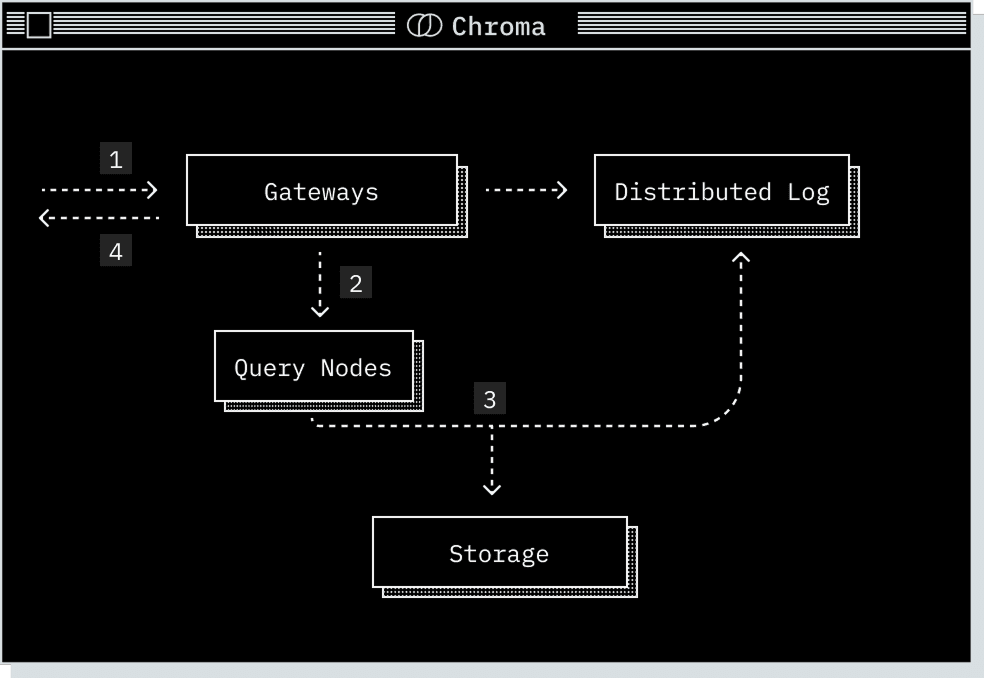
1
Request arrives at the gateway, where it is authenticated, checked against quota limits, rate limited and transformed into a logical plan.
2
This logical plan is routed to the relevant query executor. In distributed Chroma, a rendezvous hash on the collection id is used to route the query to the correct nodes and provide cache coherence.
3
The query executor transforms the logical plan into a physical plan for execution, reads from its storage layer, and performs the query. The query executor pulls data from the log to ensure a consistent read.
4
The request is returned to the gateway and subsequently to the client.
Write Path
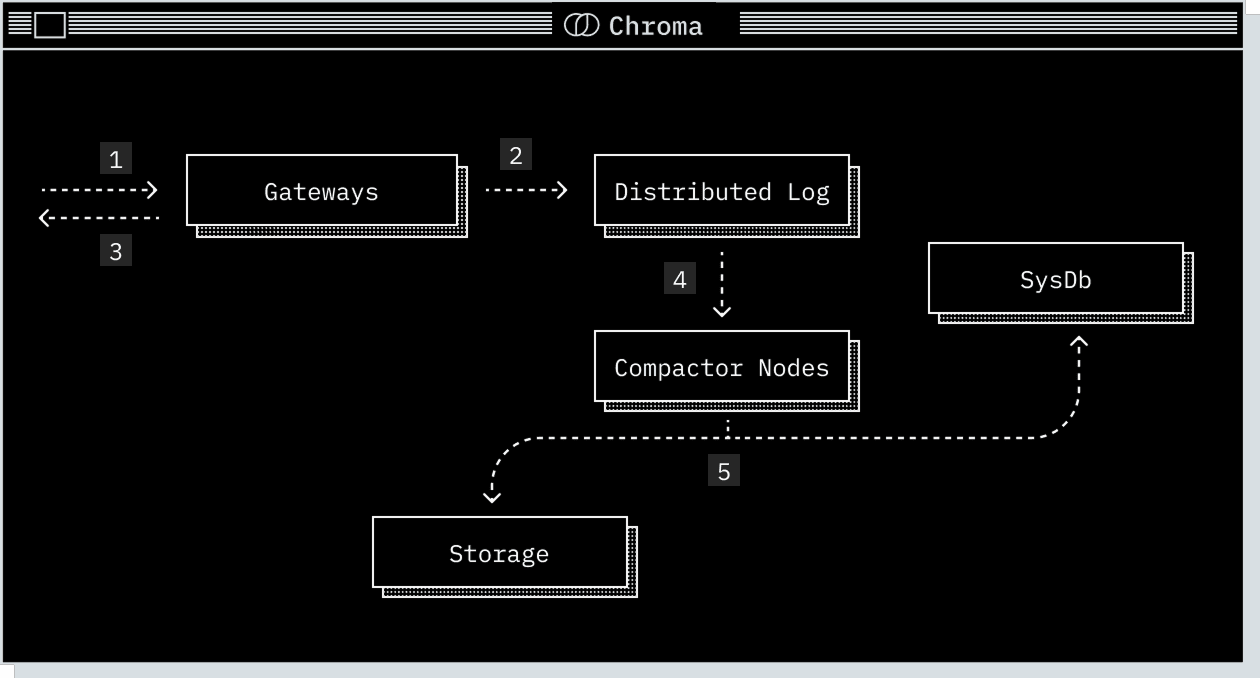
1
Request arrives at the gateway, where it is authenticated, checked against quota limits, rate limited and then transformed into a log of operations.
2
The log of operations is forwarded to the write-ahead-log for persistence.
3
After being persisted by the write-ahead-log, the gateway acknowledges the write.
4
The compactor periodically pulls from the write-ahead-log and builds new index versions from the accumulated writes. These indexes are optimized for read performance and include vector, full-text, and metadata indexes.
5
Once new index versions are built, they are written to storage and registered in the system database.